
We are excited to announce Nomic Embed Vision v1 and Nomic Embed Vision v1.5: high quality, fully replicable vision embedding models that share the same latent space as our popular Nomic Embed Text v1 and Nomic Embed Text v1.5 models.
This means that all existing Nomic Embed Text embeddings are now multimodal; Nomic Embed Text embeddings can be used to query the new Nomic Embed Vision embeddings out of the box, and visa versa. Together, Nomic Embed is the only unified embedding space that outperforms OpenAI CLIP and OpenAI Text Embedding 3 Small on multimodal and text tasks respectively.
You can use the Nomic Embed models to:
With a vision encoder of just 92M parameters, Nomic Embed Vision is ideal for high volume production use cases alongside the 137M Nomic Embed Text.
Additionally, we have open-sourced the training code and replication instructions for Nomic Embed Vision to enable researchers to reproduce and build upon our models.
Existing multimodal models like CLIP have impressive zero-shot multimodal capabilities. However, CLIP text encoders perform poorly outside of image retrieval tasks, like on MTEB, a benchmark that measures the quality of text embedding models. Nomic Embed Vision is designed to overcome these limitations by aligning a vision encoder to the existing Nomic Embed Text latent space.
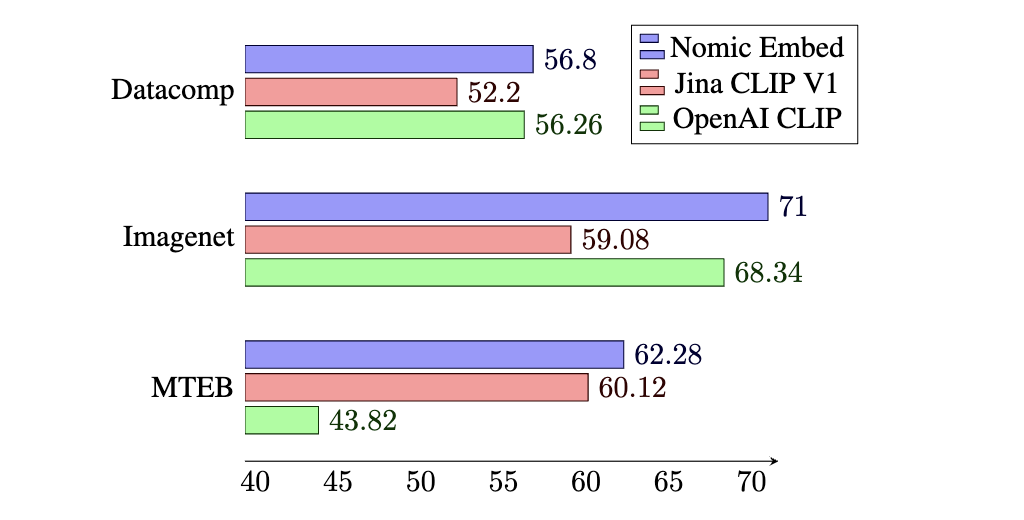
The result is a unified multimodal latent space that achieves high performance on image, text, and multimodal tasks, as measured by the Imagenet 0-Shot, MTEB, and Datacomp benchmarks. This unified latent space outperforms the modality specific latent spaces of models like OpenAI Clip and OpenAI Text Embedding 3 Small, and making it the first open weights model to do so.
| Model | Imagenet 0-shot | Datacomp Avg. | MTEB Avg. |
|---|---|---|---|
| Nomic Embed v1 | 70.70 | 56.7 | 62.39 |
| Nomic Embed v1.5 | 71.0 | 56.8 | 62.28 |
| OpenAI CLIP ViT B/16 | 68.34 | 56.26 | 43.82 |
| OpenAI Text Embedding 3 Small | N/A | N/A | 62.26 |
| Jina CLIP v1 | 59.08 | 52.20 | 60.12 |
Nomic Embed Vision powers multimodal search in Atlas. To showcase the power of multimodal vector search, we uploaded a dataset of 100,000 images and captions from CC3M, and found all the animals that are cute to cuddle with:
This query demonstrates Nomic Embed has a semantic understanding of both the question being asked and the content of the images!
Try it out yourself: https://atlas.nomic.ai/data/nomic-multimodal-series/cc3m-100k-image-bytes-v15/map/ad24e7d9-4e82-484d-a52c-79fed0da2c60#iK2R
Multimodal embedding models are trained contrastively on large-scale image-caption datasets. These Contrastive Language Image Pretrained (CLIP) models learn relationships between images and text by learning to predict image-caption pairs. Similar to text embedding models, a large batch size (16k-32k) and a large dataset (400M image-text pairs and larger!) are used to train CLIP models.
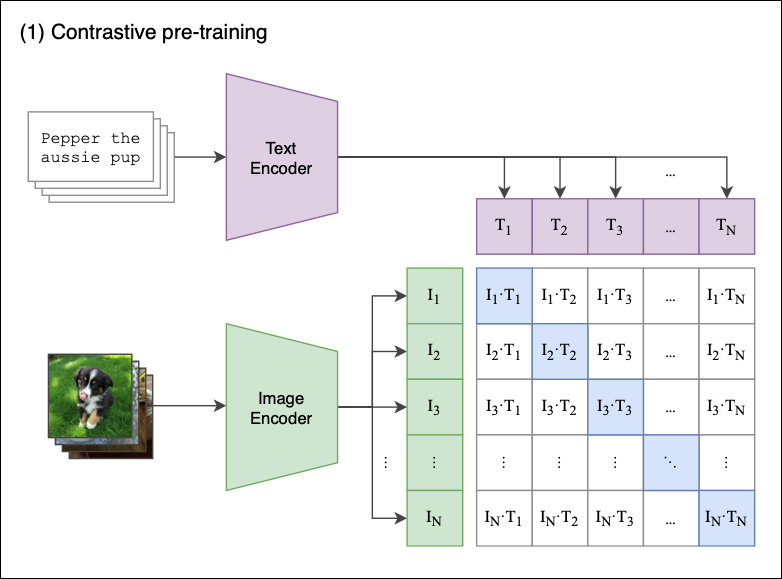
For example, OpenAI's CLIP model was trained on 400 million image-text pairs for 32 epochs, totaling ~13 billion image-text pairs seen during training. While existing CLIP models excel on tasks like zero-shot multimodal classification and retrieval, they underperform on unimodal text tasks like semantic similarity and text retrieval.
To address this shortcoming, we trained Nomic Embed Vision, a vision encoder that is compatible with Nomic Embed Text, our existing long-context text encoder. Training Nomic Embed Vision requires aligning a vision encoder with an existing text encoder without destroying the downstream performance of the text encoder.
We iterated on several approaches to solving this challenge. In each approach, we initialized the text encoder with Nomic Embed Text and the vision encoder with a pretrained ViT. We experimented with:
Ultimately, we found that freezing the text encoder and training the vision encoder on image-text pairs only yielded the best results and provided the added bonus of backward compatibility with Nomic Embed Text embeddings.
We trained a ViT B/16 on DFN-2B image-text pairs for 3 full epochs for a total of ~4.5B image-text pairs. Our crawled subset ended up being ~1.5 billion image-text pairs.
We initialized the vision encoder with Eva02 MIM ViT B/16 and the text encoder with Nomic Embed Text. We trained on 16 H100 GPUs, with a global batch size of 65,536, a peak learning rate of 1.0e-3, and a cosine learning rate schedule with 2000 warmup steps.
For more details on the training hyperparameters and to replicate our model, please see the contrastors repository, or our forthcoming tech report.
Nomic Embed Vision was trained on Digital Ocean compute with early experiments on Lambda Labs compute clusters.
The original CLIP paper evaluated the multimodal model across 27 datasets including Imagenet zero-shot accuracy. Since then, progress on multimodal evaluation progressed with the introduction of the Datacomp benchmark. Much like how MTEB is a collection of tasks used to evaluate text embeddings, Datacomp is a collection of 38 image classification and retrieval tasks used to evaluate multimodal embeddings. Following Datacomp, we evaluated Nomic Embed Vision on the 38 downstream tasks, and found that Nomic Embed Vision outperforms previous models including OpenAI CLIP ViT B/16 and Jina CLIP v1.
We have released two versions of Nomic Embed Vision, v1 and v1.5, which are compatible with Nomic Embed Text v1 and v1.5, respectively. All Nomic Embed models with the same version have compatible latent spaces and can be used for multimodal tasks.
We are releasing Nomic-Embed-Vision under a CC-BY-NC-4.0 license. This will enable researchers and hackers to continue experimenting with our models, as well as enable Nomic to continue releasing great models in the future. As Nomic releases future models, we intend to re-license less recent models in our catalogue under the Apache-2.0 license. For inquiries regarding commercial or production use, please reach out to sales@nomic.ai.
In addition to using our hosted inference API, you can purchase dedicated inference endpoints on the AWS Marketplace. Please contact sales@nomic.ai with any questions.
Nomic Embed can be used through our production-ready Nomic Embedding API.
You can access the API via HTTP and your Nomic API Key:
curl -X POST \
-H "Authorization: Bearer $NOMIC_API_KEY" \
-H "Content-Type: multipart/form-data" \
-F "model=nomic-embed-vision-v1.5" \
-F "images=@<path to image>" \
https://api-atlas.nomic.ai/v1/embedding/image
Additionally, you can embed via static URLs!
curl -X POST \
-H "Authorization: Bearer $NOMIC_API_KEY" \
-d "model=nomic-embed-vision-v1.5" \
-d "urls=https://static.nomic.ai/secret-model.png" \
-d "urls=https://static.nomic.ai/secret-model.png" \
https://api-atlas.nomic.ai/v1/embedding/image
In the official Nomic Python Client after you pip install nomic, embedding images is as simple as:
from nomic import embed
import numpy as np
output = embed.image(
images=[
"image_path_1.jpeg",
"image_path_2.png",
],
model='nomic-embed-vision-v1.5',
)
print(output['usage'])
embeddings = np.array(output['embeddings'])
print(embeddings.shape)
...
“Out beyond our ideas of tasks and modalities there is a latent space. I’ll meet you there."
